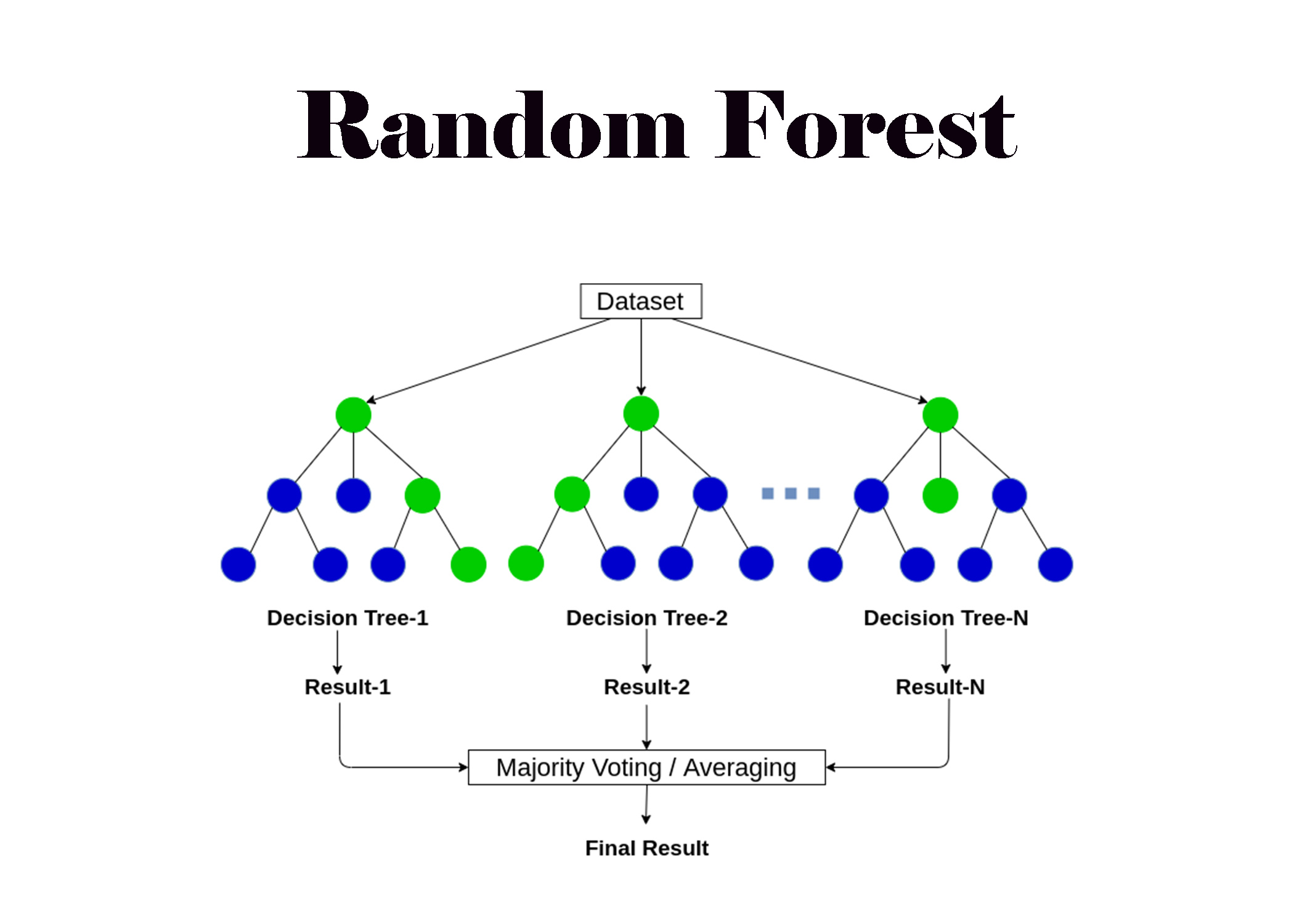
Random forests or random decision forests are an ensemble learning method for classification, regression and other tasks that operates by constructing a multitude of decision trees at training time. For classification tasks, the output of the random forest is the class selected by most trees. For regression tasks, the mean or average prediction of the individual trees is returned.
Implementation :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import numpy as np
from collections import Counter
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_blobs
from DecisionTree import DecisionTree
class RandomForest :
def __init__ ( self , nbr_trees , min_Samples_to_Split = 2 , maximum_Depth = 100 , nbr_features = None ):
self . nbr_trees = nbr_trees
self . min_Samples_to_Split = min_Samples_to_Split
self . maximum_Depth = maximum_Depth
self . nbr_features = nbr_features
def fit ( self , x , y ):
self . trees = []
for i in range ( self . nbr_trees ):
tree = DecisionTree ( min_Samples_to_Split = self . min_Samples_to_Split , maximum_Depth = self . maximum_Depth , nbr_features = self . nbr_features )
x_i , y_i = self . randomSubSet ( x , y )
tree . fit ( x_i , y_i )
self . trees . append ( tree )
def randomSubSet ( self , x , y ):
nbr_samples = x . shape [ 0 ]
indexes = np . random . choice ( nbr_samples , nbr_samples , replace = True )
return x [ indexes ] , y [ indexes ]
def predict ( self , x ):
trees_Predictions = np . array ([ t . predict ( x ) for t in self . trees ])
trees_Predictions = np . swapaxes ( trees_Predictions , 0 , 1 )
y_hat = np . array ([ Counter ( t_Predictions ). most_common ( 1 )[ 0 ][ 0 ] for t_Predictions in trees_Predictions ])
return y_hat
Testing The Model :
1
2
3
4
5
6
7
8
9
10
def accuracy ( y_true , y_pred ):
return np . sum ( y_true == y_pred ) / len ( y_true )
x , y = make_blobs ( n_samples = 100 , n_features = 10 , centers = 10 , random_state = 0 )
x_train , x_test , y_train , y_test = train_test_split ( x , y , test_size = 0.1 )
R_Forest = RandomForest ( nbr_trees = 10 )
R_Forest . fit ( x_train , y_train )
y_hat = R_Forest . predict ( x_test )
print ( "Model Accuracy : " , accuracy ( y_test , y_hat ))